Network Function Virtualization (NFV) is being keenly followed by the telecom industry and proof of concept implementations are already in process. NFV is an engineering approach of building telecom systems (Network Entities or Network Functions) by making effective use of commodity compute/storage/network resources while reducing (or removing) dependency on specialized platforms. In the present scenarios, where new applications are difficult to conceptualize and more focus is maximizing the revenue from already deployed resources, NFV based solution has high potential to make a difference. The approach of building the Virtualized Network Function (VNF) involves decoupling the logical network functions (NF) from the hardware platform and moving the software-only implementation of these functions to virtualized resources hosted on general purpose high performance servers.
Figure 1: NFV Simplified View
Some of the benefits of NFV are below:
Sharing of deployment platforms for multiple VNFs and hence potential cap-ex reduction for starting new services
Consolidation of hardware used for different VNFs and hence reduction in both real estate cost and power cost
Possibility of instantiating new VNF(s) on already deployed HW resources and hence faster commissioning of new services
Software only implementation of NF(s) decoupled from HW leading to more agile and flexible deployment models
Remote life cycle management of NFV infrastructure helps in reducing the number of actual site visits thereby improving the operational efficiency.
Issues and perceived challenges
The telecom vendors are currently developing proof-of-concept for moving existing network functions to virtualized infrastructure and we believe there are quite a few challenges during the implementation and deployment phase. We will discuss the aspects that come into play when the different network functions are deployed in virtualized infrastructure and not the functional or protocol related aspects which are more or less the same irrespective of the physical or virtualized infrastructure. Some of the issues and challenges we foresee are discussed below:
Constraints of existing Architecture and retrofitting issues
Most of the legacy systems are architected with an assumption that NF has exclusive access to the platform and possibility of sharing the physical resources (CPU, NIC, disk) amongst independent NFs (multi-tenancy principle) is not considered at all. At times the HW resources (such as BSP, HW accelerator, etc.) are directly controlled by the NF (as part of the application specific processing). Some of the specific issues are listed below:
1. Specific dynamic behavior in terms of task interactions and task scheduling may be assumed to meet real time performance at the time of designing the existing physical network function and sharing of the HW platform with other contenting NFs would cause some performance impacts (referred to as noisy neighbor problem). The virtualization frameworks (i.e. hypervisors) provide some level of isolation between different virtual machines (VNF container); however the same execution environment as that in case of physical network function may not be ensured.
2. The existing NE would mostly be scalable; however the architecture may not support the dynamic scaling-in/ scaling-out in response to decrease/increase of the traffic. The load distribution algorithm would typically be static and assume all the installed physical servers are available for use resulting in under-utilization of each of the servers. Some amount of re-engineering would be needed to make use of ‘elastic’ nature of the virtual infrastructure.
Some of the processing in a NE may require specialized processors (such as DSP or NP). For e.g. some of the RF chain processing in the base station would need DSP or data path processing in a typical router would need a NP for fast path. Migrating such specialized processing to NFV infrastructure may not viable (for technical or commercial reasons) and partial virtualization for such components/layer would have to be used. In the initial NFV deployment phase, partial virtualization may also be adopted as a general strategy to manage some of the performance related risks.
Management of Virtualized infrastructure and the NFs
The management framework in the traditional network typically has Element Management function associated with each NE and multiple EMs within the domain of a given network operator reports to a NM system. The existing EM functions assumed a very tight coupling between actual network function and the platform hosting the function. Some of the side effects of this are listed below:
The operational state of the underlying platform being considered the same as that of the NF with no separation between the cause and effect at times
The topological view showing different NEs/NFs in their physical form (usually for NEs using custom build platforms) in the form of hierarchy of HW modules, rather than showing the NFs as being overlaid over the physical infrastructure
The EM fault management function mapping the platform fault directly to the NF/NE rather than implementing the alarm correlation logic to associate the root cause and the impacted function(s).
The management model will have to be extended to include the platform (NFV infrastructure) and the NF container (VNF instance) as additional managed objects. New logical functions Virtualized Infrastructure Manager and VNF Manager respectively introduced specifically manage these managed objects (refer to NFV reference architecture [3]).
Meeting Carrier Grade Expectations
The present day network infrastructure provides reliable service and meets the availability figures of 4’9s to 5’9s. The high capacity servers have been commonly used for IT services and enterprise class of application (with availability of the order of 2’9s to 3’9s). The NFV infrastructure will be build using such server may not be able to meet the stringent availability figures.
Further virtualized infrastructure allows very agile life cycle management to allow just in time creation of VM to host the VNF; in the event of failure. The availability approach relies on spawning new instances. This is quite different than the traditional HA architecture used in telecom system with carrier grade systems.
In the HA architecture, while platform redundancy is used to avoid SPOF, all the components (hardware+ software) are hardened to prevent failures and application specific state replication is implemented to ensure continuity of operations (may include ongoing transactions such as calls/ sessions) in an even to failure. This HA support (both at the platform level as well as the application level) will have to be ported to the newer environment (within the NFV infrastructure)
It may be noted that, a number of COTS platforms (such as Wind River Titanium server) are coming up for NFV infrastructure, specifically designed to meet the carrier grade requirements.
Integration and Testing issues
Traditionally different NFs were deployed as distinctly visible entities with well-defined interface reference points. A number of integrations tools (such as protocol analyzers, data probes) are based on such controllable and observation reference points. Most of the integration tools assume easy access to these interface reference points; however in the NFV model one or more NFs related to an end-to-end service may be assigned to same high end HW resource and the access to the reference point would be restricted. Some of the virtual switches address this issue by forwarding all the traffic on the virtual NIC to the physical NIC (using Virtual Ethernet Port Aggregator approach [5]) for facilitate the tapping of these interface reference point.
System performance testing under load conditions in the deployment configuration will pose some challenges. In the lab, it will not be possible to create an environment equivalent that of the actual deployment as other VNFs sharing the same infrastructure is either unknown or cannot be instantiated. There is no work around to address the former, while the latter can be addressed by hosting some additional VNFs in the same VNF infrastructure as part of the system testing setup.
HSC team has significant experience of developing NEs (Network Elements) for telecom services per the 3GPP, NGIN and OMA standards. Some of the specific examples are HLR/HSS, SCP (Pre-paid IN charging), IM-SM gateway, PTT server and also the EMS/NMS, BSS/OSS for telecom systems. HSC presently has an operational in-house virtualized infrastructure based on VMware (vSphere) solutions. This operational experience in addition to the NE specific know-why has been helping in executing NFV related consulting and implementation assignments.
References
[1] Network Function Virtualization, Introductory White Paper
[2] ETSI GS NFV 001, Network Function Virtualization (NFV) Use cases
[3] ETSI GS NFV 002, Network Function Virtualization (NFV) Architectural Framework
[4] ETSI GS NFV 003, Network Function Virtualization (NFV) Requirements
[5] Network Virtualization and Software Defined Networking for Cloud Computing: A Survey
Thank You!
Thank you for contacting us. We will get back to you soon.
X
Subscribe Form
Thank You!
Thank you for contacting us. We will get back to you soon.
 Product Engineering Services Customized software development services for diverse domains
Product Engineering Services Customized software development services for diverse domains

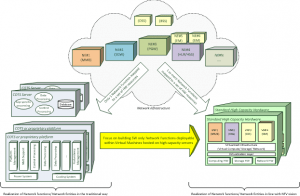 Figure 1: NFV Simplified View
Figure 1: NFV Simplified View

