Overview
Apache Spark is an open-source framework for big data processing and analytics on a distributed computing cluster. It combines SQL, batch, streaming, and analytics under one umbrella to quickly develop a variety of big data applications.
Apache Hadoop is also an open-source framework for distributed storage and processing of big data in a cluster environment. The core of Apache Hadoop consists of a storage part HDFS (Hadoop Distributed File System) and a processing part (MapReduce). Apache Hadoop has been traditionally used for big data MapReduce jobs.
While both Spark and Hadoop are fault-tolerant, one of the basic and yet a major difference between the two big data computing frameworks is the way they do data processing and computing. While Hadoop stores data in disk, Spark stores data in-memory. Due to this in-memory processing, Spark is 10-100 X faster than Hadoop.
So does this mean Spark is going to replace Hadoop in future?
Hadoop MapReduce Limitations
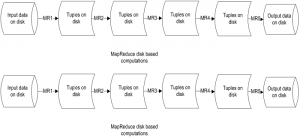
Since Hadoopís MapReduce is based on disk based computing, it is more suitable for single pass computations. It is not at all suitable for iterative computations, where output of one algorithm needs to be passed to another algorithm.
To run iterative jobs, we need a sequence of MapReduce jobs where the output of one step needs to be stored in HDFS before it can be passed to the next step. So the next step cannot be invoked until the previous step has completed.
Apart from the above limitations, Hadoop needs integration with several other frameworks/tools to solve big data uses cases (like Apache Storm for stream data processing, Apache Mahout for machine learning).
What Makes Spark Superior To Hadoop?
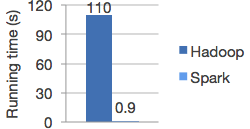
One of the major advantages of using Apache Spark is speed. Applications can run 100X faster in memory and 10X faster while running on disk [1]. Unlike Hadoop, it stores the intermediate results in memory (instead of disk). This significantly reduces number of disk I/Oís. The image below shows a glimpse of the logistic regression in Hadoop and Spark and they are starkly differentiated by the running times.
Logistic Regression in Hadoop and Spark[1]
In order to achieve faster in-memory computations, Spark uses the concept of RDD (Resilient Distributed Dataset). Spark partitions the data in multiple datasets which can be distributed across clusters and can be quickly re-constructed in case of any node failures.
From the Spark academic paper: “RDDs achieve fault tolerance through a notion of lineage: if a partition of an RDD is lost, the RDD has enough information about how it was derived from other RDDs to be able to rebuild just that partition.” Contrary to this, Hadoop replicates data across nodes of the cluster for redundancy which involves lot of network I/O also.
Since Apache Spark is compatible with Hadoop data, it can run in Hadoop clusters through YARN apart from Spark’s in-built standalone mode. Apart from processing data from local file system, Apache Spark can process data from HBase, Cassandra, Hive (and also any Hadoop InputFormat).
This makes it easy to migrate existing Hadoop applications to Spark.
Apart from this, Spark also offers the following features:
- Inbuilt libraries for processing of streaming data
- Support of SQL
- Machine learning libraries
- Graph analysis
- Interactive shell
- Interactive analytics
- Multi-language support (Python, Java, Scala, R)
- Supports lazy evaluation using DAG (Direct Acyclic Graph)
Is Spark Going To Replace Hadoop?
Due to in-memory computations, Spark uses more RAM instead of disk I/O. So Spark deployments need high-end physical machines. So for the data which does not fit into memory, we still need disk-based computations. In case RAM available is less than the data to be processed, Spark does provide disk-based data handling.
Spark provides advanced, real-time analytics framework where MapReduce lacks. To the contrary, MapReduce is well suited for large data processing where quick processing is not a key parameter. As the volume of data grows day by day and coming with high velocity, MapReduce falls short when it comes to low latency analytics.
So, it is clear that Sparkís performance is better when the entire data to be processed fits well in the memory. Hadoopís MapReduce is designed for data that doesnít fit in the memory and can run alongside other services.
Conclusion
Considering all these advantages and constraints of both Spark and MapReduce, it seems both the worlds are here to co-exist and complement each other, rather than Spark replacing Hadoopís MapReduce.
Spark is more towards high-performance plain data processing, where it can do both real-time and batch-oriented processing. Hadoop MapReduce is more inclined towards pure batch processing. For real-time processing, Apache Spark is required whereas machine learning (filtering, clustering, classification, etc.) can be achieved via Apache Mahout (Spark has inbuilt MLib).
Being a single execution engine, even though Spark has an upper hand, it cannot be used on its own. It would still need HDFS for data storage. Choosing between them depends on the variables that we are going to use and the problem we need to solve. We can always leverage the best of both the worlds.
Spark Over Hadoop
Now since Apache Spark is seen as a complement to the Hadoop ecosystem, there could be several use cases where Hadoopís massive semi-structured data storage in HDFS can be combined with Apache Sparkís faster execution.
One such scenario is ìLambda Architectureî implementation of big data analytics systems where a massive distributed storage is required for batch processing of historical data (considering historical data is growing many folds over the time). In such implementations, real time stream processing and machine learning is required to provide an actionable in-sight in near real time [5]
References
- 1. http://spark.apache.org/
- 2. https://hadoop.apache.org/
- 3. http://vision.cloudera.com/mapreduce-spark/
- 4. https://amplab.cs.berkeley.edu/projects/spark-lightning-fast-cluster-computing/
- 5. http://lambda-architecture.net/
 Product Engineering Services Customized software development services for diverse domains
Product Engineering Services Customized software development services for diverse domains