A traditional asset tracking solution which could barely support tracking 10,000 assets, can be re-engineered to track millions of assets, by using bigdata technologies.
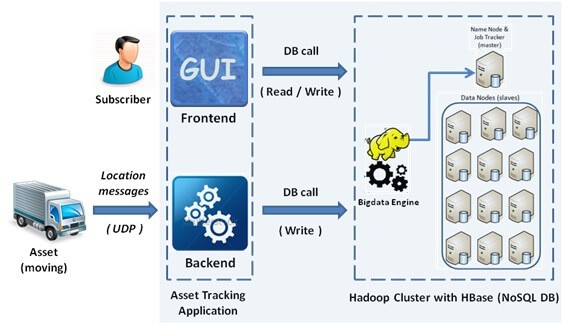
Consider an Asset Tracking System which offers ‘location-based asset tracking’ as a Service. The service facilitates subscribers to track movement of their assets through a web-based interface. The web interface provides a geographical map based console to subscribers, which can be used to view the current location of assets on detailed maps.
The Location of the assets is recorded from the GPS coordinates sent by transmitters installed on each asset. In such systems, assets report their location at set intervals which can range from few seconds to minutes. A User Interface running in a browser fetches map definitions from Map Servers through its JavaScript APIs and displays the assets on the map. The User Interface fetches asset id, asset type and coordinates of the assets registered to that subscriber. The subscriber can view the movement of the assets during any period of time (from a few hours to months).
Figure 1: Traditional architecture
Such a system requires storing large sets of location data and the ability fetch data from a database as and when a user queries for it. Additionally, such systems periodically generate Charging Data Records (CDR) for each asset monitored so that the subscriber can be billed by the operator. Since the subscriber needs the ability to query on data which can be upto an year old, in a typical implementation, given the enormous volume of location and CDR data, the files are stored in a high volume storage devices connected to a network such as Network Attached Storage (NAS).
The NAS has high storage capacity; however, it has poor response time. Multiple NAS servers can be added to enhance storage capacity, but that comes at significant added cost. Considering poor response time of such (high-volume) storage devices, an in-memory database is used to facilitate real-time throughput and display of the received location data.
The key challenges of these implementations are:
User Interface is required to display multiple asset-types at any given instant.
Time interval for queries corresponds to a mix of current data and old data, which requires joining location data in the NAS and in-memory database.
Information that needs to be displayed in the map-view requires multiple queries to the database (like count of received emergency messages which are unacknowledged, last received emergency message, last received text message, last sent text message, etc.)
Maintaining data redundancy
Bigdata technologies are well suited to address the challenges mentioned above. NoSQL databases (like HBase, Mongo DB, Cassandra and others) which are typically used to handle the high-traffic of social-networking sites are suitable candidates to replace a typical RDBMS in such a system. NoSQL DB can easily store large amounts of data, without sacrificing throughput. The speed of storage and retrieval of data eliminates the need to have an in-memory database. It also eliminates the need to periodically evict data from it and to join its data with NAS stored data for mixed queries.
Figure 2: Alternate design based on Bigdata technologies
The complete storage of location data and other related data such as CDRs etc can be moved into a Hadoop-based cluster which automatically provides data redundancy and unlimited scalability without trade- off in the performance. Additionally, offline tasks like generating CDR files from stored location data can be accomplished by deploying mapreduce tasks which can run on various data-nodes in parallel on the offline data.
In such an implementation, the backend will receive location messages from the assets and store the data in high throughput data storage such as Hadoop Distributed File System (HDFS). HDFS would split the data into various blocks for appropriate storage. Data in HDFS would be scattered over numerous nodes for built-in fault tolerance. HDFS has one master/namenode and numerous slave/datanodes. Namenode stores metadata and datanodes store data blocks. Namenode and datanodes reside on commodity servers and each node/server offers local storage and computation. For the user queries, the GUI submits a query to the data storage.
Figure 3: Drill down into the Bigdata-based data storage
The query is submitted to the master node. Master node uses ‘map’ process to assign sub-jobs to slave nodes. Slave nodes may still further assign to other slave nodes. The sub-jobs are executed in parallel on each node in the cluster against the node’s local data set. The slaves complete their tasks and return back results to the master. The master assembles/aggregates the results using the ‘reduce’ process. Offline tasks like periodically generating CDRs from the location data, can also be implemented using mapreduce. A map task can be defined that will group data collected during last time interval, against individual asset id. This can happen in parallel on each datanode.
A reduce task can be defined to sum up the data for each asset id and store it in CDR files. (The CDR files are used for billing subscribers for the usage.) While traditional implementations get overloaded in tracking even ten thousand assets, this design can easily scale to the order of a million assets. Traditional implementations require expensive NAS, whereas in the new design hadoop cluster can be scaled to any size in the order of terabytes and petabytes, by just adding more commodity boxes in the hadoop cluster. Through parallel computing, mapreduce tasks will ensure that there is no impact on processing of the location data. Thus Bigdata-based technologies can enable the service to track much larger set of assets, with a simpler and more efficient design.
Thank You!
Thank you for contacting us. We will get back to you soon.
X
Subscribe Form
Thank You!
Thank you for contacting us. We will get back to you soon.
 Product Engineering Services Customized software development services for diverse domains
Product Engineering Services Customized software development services for diverse domains

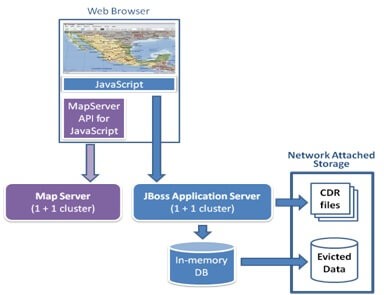 Figure 1: Traditional architecture
Figure 1: Traditional architecture