
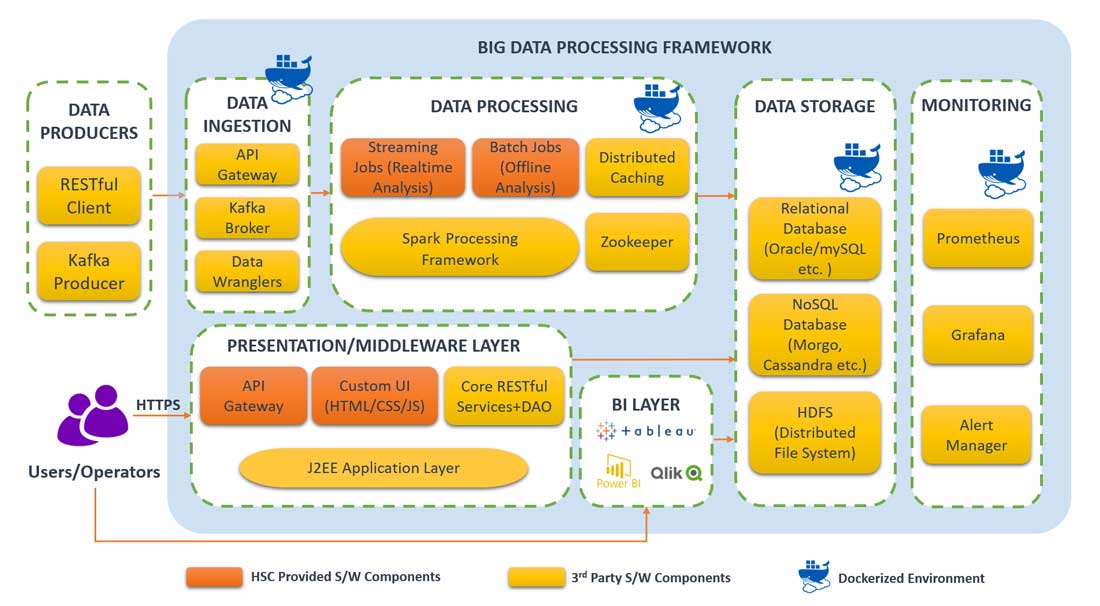
Organizations all over the world are looking at having a centralized data processing framework. All the enterprise data must go into this pipeline and then get processed as per the pre-configured rules. Data access (raw and processed) must be controlled all the time. This pattern enables greater coordination among different teams/departments within the same enterprise. It also allows the enterprises to share the data processing infrastructure among the teams which brings down the overall cost.
HSC’s data processing framework is highly suitable for such large-scale enterprise data management needs. The framework facilitates ingestion of data and processing of it in real-time. Batch jobs can be executed to generate time-consuming non-real-time reports. Historical data can be archived on HDFS/S3 and retrieved as and when needed. The framework allows great coordination between different data processing jobs using Kafka.


