The MySQL cluster demands at least 4 nodes to be present for deploying a High Available MySQL database cluster. The typical configuration of any enterprise application is a 2 Node solution (Active-Standby mode or Active-Active Mode). The challenge lies in fitting the MySQL Clsuter Nodes in the 2 Nodes offering the application services and to make it work in that configuration with no single point of failure.
MySQL Cluster
MySQL Cluster is a technology that enables clustering of in-memory databases in a “shared-nothing system”. By “shared-nothing” it is meant that each node has its own storage area. Note that the use of the shared storage mechanisms such as network file systems are not supported and recommended by MySQL. For High Availability there are at least 2 nodes on which the data is stored locally so that in case of one node failure the data is still accessible from the other available nodes. One of the data node acts as “Master” and the rest ones act as “Slaves”. These data nodes communicate with each other to replicate the data across the data nodes so that the change done on one node is also visible on rest of the nodes.
MySQL Cluster integrates the standard MySQL server with an in-memory clustered storage engine called NDBCluster (Network DataBase).
There are following actors in a MYSQL Cluster:
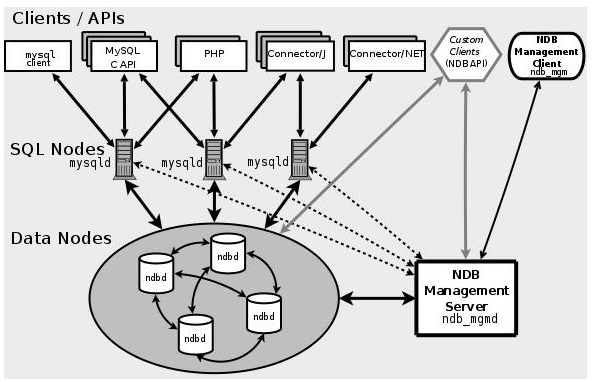
Clients/APIs
SQL Nodes
Data Nodes
NDB Management Node
The figure below depicts these actors with the corresponding interactions
Clients/APIs
These are the clients/applications that actually use the MySQL Cluster. They connect through various methods such as MySQL C APIs, Java connectors. All of these clients connects to the SQL Nodes which in turn connects with the Data Nodes for accessing any data stored in the MySQL Cluster.
There is a special API provided by MySQL known as NDBAPI which directly connects with the Data Node bypassing the SQL Node. This increases the read/write operations performance significantly and is recommended to be used for high throughput applications which require very high rates for read/write.
SQL Node
This is a node that accesses the cluster data. In the case of MySQL Cluster, an SQL node is a traditional MySQL server that uses the NDBCLUSTER storage engine. An SQL node is a mysqld process started with the –ndbcluster and –ndb-connectstring options.
Data Node
This type of node stores cluster data. There are as many data nodes as there are replicas, times the number of fragments. For example, with two replicas, each having two fragments, you need four data nodes. One replica is sufficient for data storage, but provides no redundancy; therefore, it is recommended to have 2 (or more) replicas to provide redundancy, and thus high availability.
NDB Management Node
The role of a management node is to manage the other nodes (Data Nodes, SQL Nodes and Client Nodes using NDBAPI). The Management node is the first node to be started in a MySQL Cluster before starting any other node. The functions it performs are:
Providing configuration data to other nodes.
Starting and stopping nodes
Starting the cluster.
Challenges
MYSQL requires at least four nodes for the cluster to work (https://www.mysql.com/products/cluster/faq.html#11)
11. How many physical servers are needed to create a minimum Cluster configuration?
A: For evaluation and development purposes, you can run all nodes on a single host. For full redundancy and fault tolerance, you would need a minimum 6 x physical hosts:
2 x data nodes
2 x SQL/NoSQL Application Nodes
2 x Management Nodes
Many users co-locate the Management and Application nodes which reduces the number of nodes to four.
This was a major limitation as the Design and Architecture demands for 2 nodes. The challenge was to accommodate all the MySQL Cluster components into 2 nodes in a High Available environment. The limitation is due to the three node architecture of Mysql Cluster. Running all the nodes (Data/SQL/Management) on one node and having one standby for them posses following potential problems:
The failure of one node will cause failure of all the three nodes at once causing the whole cluster to fail. What MySQL guarantees is that there is no single point of failure but does not guarantee if two nodes fail at the same time, for e.g. one Data Node and one Management Node failing precisely at the same time.
Correct set of configuration for all the MYSQL Cluster components in both the nodes so that the cluster can work properly without any issues. Note that there are always high chances of incorrect configuration as the IP Addresses were always be different as per the customer setups.
The failover of the Management Server. There was one Management Server that has to run in two nodes. This could cause a single point of failure. Although a cluster can still continue after it is started and the Management Server fails but still there are some important tasks that are done by the Management Server which are required at runtime also:
Provide status information about the cluster and allow to use the ndb_mgm for various maintenance tasks like taking a hot backup
Own the cluster config file (therefore it must be running to start a node)
Arbitration in case of a potential split-brain
Logging
Incorrect source IP Address chosen by the NDBD and MySQLD for connecting to the Management Server. The NDBD and the MySQLD components use ANY Address to bind to. This was a necessity but it caused issues when they try to connect to the Management Server. The Management server binds to a Virtual IP (REPNW_VIP) which is accessible from the other node also. But when the MySQLD and NDBD tries to connect with Management Server it chooses the source IP of the TCP packet as the REPNW_VIP itself on the node which has the REPNW_VIP associated with it. So essentially the packet’s source and destination IPs are same (REPNW_VIP).The Management Server could not find the corresponding node in its configuration and replies back with error causing the NDBD and MySQLD to shutdown. Note that NDBD and MySQLD can bind to a specific IP address in case of multiple interface case which could have solved this issue but for running it on two node it was a necessity to bind them on ANY Address.
Solution
The solution that was implemented for the challenges mentioned above.
The configuration implemented was to run the MySQLD and NDBD on each node. The Management Server was run on the Active Node (Note that the 2 nodes run in Active-Standby configuration). The Active Node is the one which is externally reachable through a virtual IP (External VIP) through which the traffic for the applications will come. The REPNW_VIP is also collocated with this External VIP so that the management server can bind to it. These constraints were possible through the Pacemaker configuration. All the resources running in a node are configured as a resource for pacemaker where constraints on the resources are put through the pacemaker configuration. Presented below is a sample configuration file (Note that the application resources are removed from this configuration).
The MySQL cluster is highly dependent on the IP Addresses, host names and node ids configuration of all the nodes. That means that the configuration has to be correct across all the nodes and the management server has to have the information about the SQL, NDB, API nodes and the other nodes needs to know where the Management server is. Since this information is not static (Note that the configuration can change in the deployment setup with respect to host names and IP Addresses) so it has to be configured during the installation process only. The installation process implemented was a 2 step process.
Golden Disk Installation: This involves installation of the OS and the all the rpms necessary to run. During this step MySQL cluster rpms are also installed and the default configuration files are placed at relevant path.
Application Package Installation: This involves installation of the application and configuring the system. All the dynamic information is taken as an input from the user and the relevant configuration files with respect to MySQL are updated during this process.
Presented below is a sample configuration file for mysqld and Management Server.
The failover of the management server is controlled through pacemaker. The Management Server needs to be run on the “Active” Node in a “Active/Standby” two node configuration. This is ensured by making Management Server a primitive resource in Pacemaker and adding a collocation rule in Pacemaker with the VIP. Note that the “Active” Node always hosts the “VIP” . colocation ndb_vip-with-ndb_mgm inf: NDB_MGMT REPNETWORK_VIP. This rule ensures that the Management Server is run where the VIP resides. This also ensures the movement of the Management Server to the other node in case of Failover/Switchover of the Active Node when the VIP moves. Note that all the other nodes contact the Management Server on the VIP only so for them they do not see this transition happening and the cluster keeps on running in case of the Active Node failures.
A simple IP tables rule solves this issue. Again since the IP Addresses can change during installation the IP table rule is also made during the installation process itself. This rule is run each time the machine reboots (entry put in rc.local).
Presented below is a sample rule
Thank You!
Thank you for contacting us. We will get back to you soon.
X
We will get back to you!
Thank You!
Thank you for contacting us. We will get back to you soon.