
From personalized recommendations to autonomous vehicles, AI’s potential to transform businesses is clear. However, the other side of this coin is a number of ethical, social, and legal challenges that will come from implementing these new age AI systems.
Unintended consequences—ranging from biased decision-making to privacy violations—can emerge when ethical guidelines are ignored during AI development. We’ve already seen real-world examples of misuse and discrimination, and these have resulted from the lack of transparency and fairness in these models.
This blog dives into the need for responsible AI, looking at the risks posed by models, data, systems, and user interactions. It also explores actionable guidelines for promoting ethical AI development, so that it works towards the interests of individuals and society.
While AI is no doubt going to revolutionize industries, diving headfirst without considering its unintended consequences is going to undermine AI. One common example of unexpected results is the hallucinations seen in LLMs. Hence, to start laying out the ethical roadmap for AI, we need to understand the risks involved with AI first.
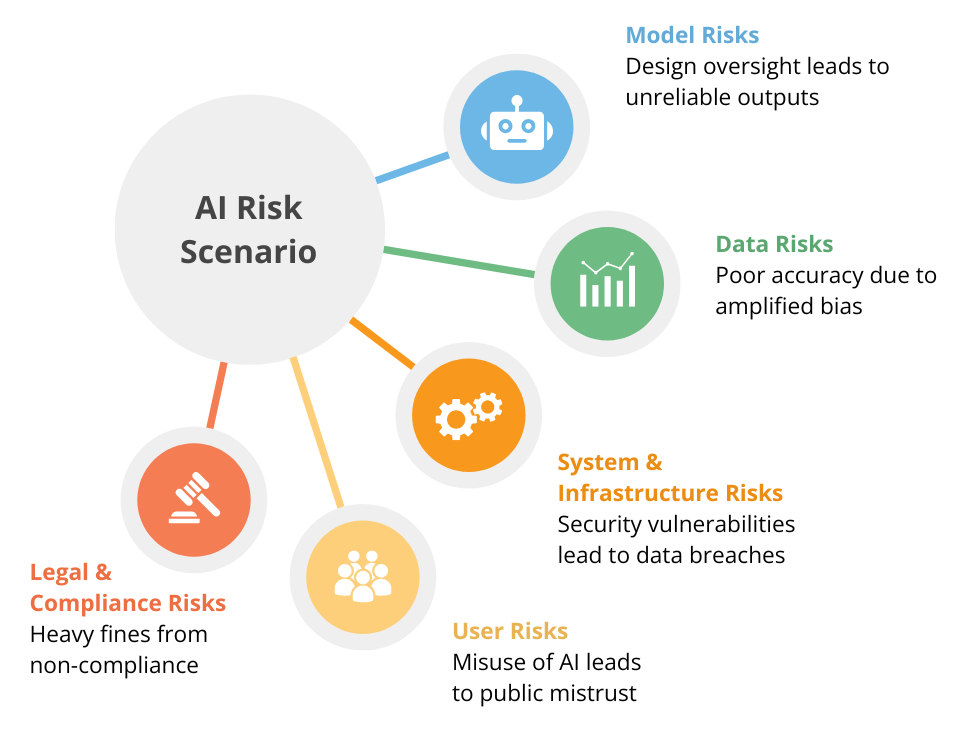
Ethics must be an integral part of model development as it informs the design, training, and performance of the model. We have already seen examples of models showing bias and discrimination, even from large players such as Google and Microsoft.
Bias actually begins from the data fed into these models, which in turn tend to amplify them. A prominent example is AI-based hiring systems, which tend to discriminate based on demographics, simply because the training data contained skewed patterns.
We have all become familiar with the term “hallucinations” after the explosion of generative AI. Unethical models can produce unreliable outputs, ranging from simply incorrect to harmful outputs. This happens when ethical oversight is ignored during training and validation.
A common issue which AI researchers come across is the “black box” nature of their models, where it is difficult to trace how an output was obtained. Instead, ethically responsible AI should account for human oversight and accountability. It should also have clear mechanisms with the appropriate controls to tackle bias and output.
LLM Observability specifically addresses this lack of oversight, bringing in processes to track aspects like performance, biases, and potential failure points. It gives the developers the ability to understand and explain some of the behaviours of these LLMs. The result is a model with fewer biases and hallucinations reaching the user.
As we discussed in the last section, bias begins with the data input into the models. With the size and complexity of these large datasets used in AI, ensuring the quality of data is crucial.
Skewed datasets are a result of unethical data collection practices. When diverse demographic groups are underrepresented or misrepresented, the model tends to reinforce this discrimination. For instance, early facial recognition systems used to struggle with darker skin tones as those demographics were only a small part of the datasets.
With strict ethical guidelines, companies may ignore user privacy while developing AI. Such AI systems may use personal data without the users’ consent. For example, this data could include users’ online activity, health records, or financial information without their knowledge.
Datasets are often incomplete or inconsistent in early stages, and may become outdated as time passes. Poor data directly impacts the system’s ability to make accurate decisions, and ongoing data curation is necessary for relevant results.
Transparency here covers how data is collected, processed, and used. AI developers must be open with all stakeholders (incl. users and regulators) on how their data is being leveraged. For example, users need to have insight into how their data is being used for targeted ads or profiling.
While we have covered the two main sources of ethical issues in AI (models and data), these systems rarely operate in isolation. They are part of a larger digital ecosystem, comprising of other interfaces, hardware, networks, and other components.
Hence for ensuring a responsible AI ecosystem, ethical considerations must also extend to how AI is incorporated into existing ecosystems.
As new AI systems are integrated into existing workflows, it must be ensured that these do not open new exploits for malicious parties.
As alluded to earlier, ethical AI integration must account for the scalability and resilience of the system to meet business needs. They must be able to accommodate growth without performance degradations.
Even the most robust AI systems can be dangerous when used irresponsibly.
Intentional Misuse: A huge concern currently is the rise of convincing deepfakes that are designed to mislead people. This, along with manipulative algorithms used by social media giants and military investment in autonomous weapons are few major concerns which necessitate ethical regulation.
Without the proper safeguards, AI systems can have unexpected results. For instance, an AI designed to optimize business processes could result in job losses.
Many industries such as healthcare, finance, and education pose strict regulations on organizations. Regulations such as GDPR and HIPAA are meant to protect critical private data of users, and AI models also need to ensure adherence to these guidelines.
Considering all the points discussed above, it is clear why ethical considerations need to be integrated in AI development. Let us now see which guidelines should be followed to develop responsible AI.
There are five core tenets on which responsible AI practices are based. These tenets help not only in mitigating risks but also in unlocking AI’s full potential for businesses.
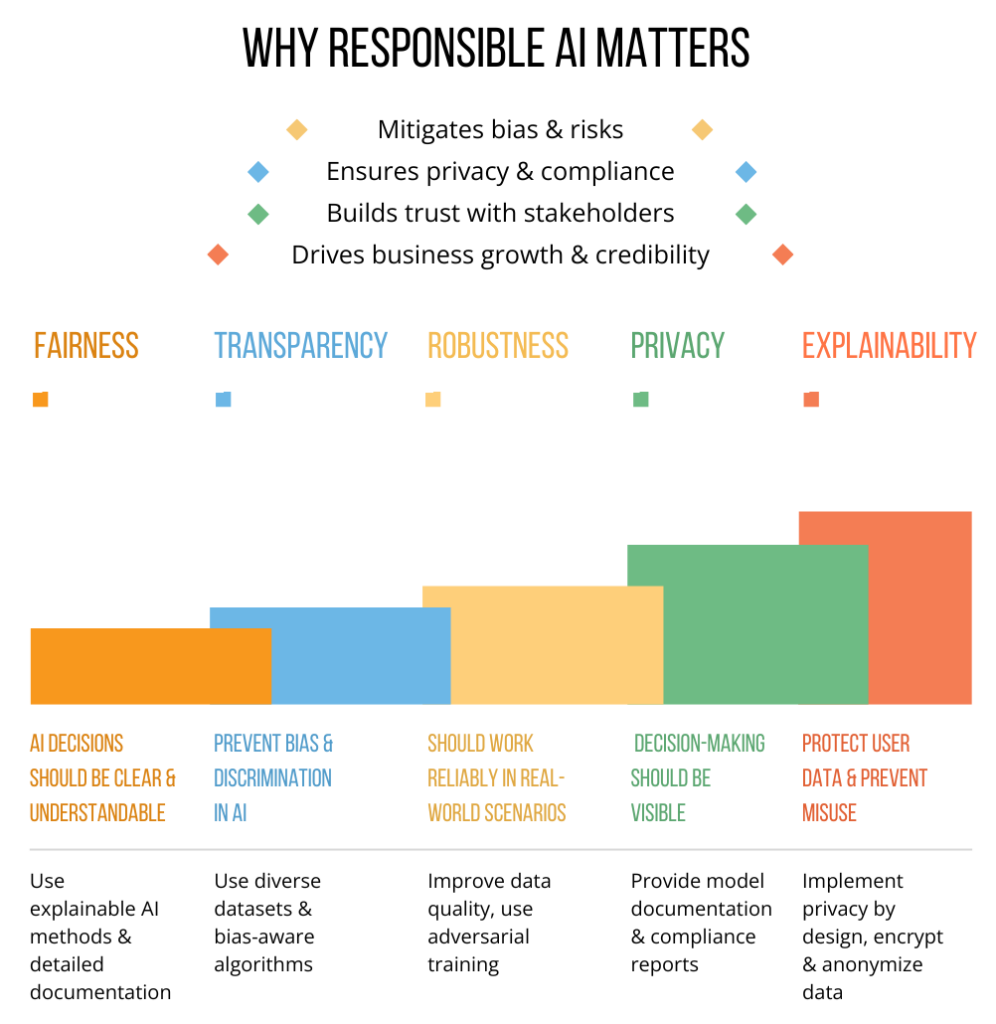
In complex AI models such as deep neural networks and large language models (LLMs), it is difficult to understand how a certain output was generated. Explainability aims to make the decisions and actions of these models clear to stakeholders. It gives developers, users, and regulators insights into the system which promotes trust, accountability, and fairness.
Here are some best practices to ensure explainability of the AI system:
This can be done by identifying high-risk applications, ensuring explanations align with the behavior, and accounting for diverse needs of various stakeholders.
Data used throughout the AI development should be transparent, including training, testing, and deployment data. Doing this gives insights into which features or data points resulted in a particular output, aiding in debugging and performance improvements.
Teams must include not only developers, but also legal, business, and ethics experts who are actively involved. This is to ensure compliance with regulations such as GDPR and the EU’s AI Act.
The fairness aspect of responsible AI deals with removing bias from ML models. As discussed earlier, these statistical models tend to exaggerate existing biases within the data, giving a systemic advantage to privileged groups. As AI is seeing use in high-stakes environments with real impact on people, it is important to keep under/oversampling in check.
Here are some steps to ensure the fairness of such systems:
As underrepresentation is a common issue with datasets, special attention must be given to include groups with systemic disadvantages. This involves regular assessment and audit of the data being used.
Algorithms that are designed to tackle biases in the data. Some methods include re-sampling data to balance demographics, tweaking the algorithm’s learning process, and adjusting predictions in post-processing.
Individuals from underrepresented groups bring diverse perspectives to the table, which may be overlooked by homogenous teams.
These groups provide the necessary ethical angle and considerations throughout the development process.
This measure relates to how AI systems can deliver stable performance and quality of results across a broad range of working conditions. It is important to ensure robustness as these AI systems work with a variety of real-world data that differs from the kind of sanitized data used while training them. For example, computer vision use cases benefit greatly from this, as real-world images contain some level of noise or other irregularities. Thus, the benefits of robustness can be observed in industries such as healthcare and autonomous vehicles, to name a few.
Here are a few ways of ensuring better robustness in AI models:
A high quality of data, which is representative and diverse affects every aspect of a model’s performance. As discussed above, this affects fairness and many other factors such as reliability and accuracy as well.
Instead of using very sanitized data for training, the models are shown some images with irregularities as well. The idea is to ensure that the model is prepared for real-world inputs that may not exhibit ideal conditions.
Methods such as L1 or L2 regularization can prevent overfitting to create simpler models that can work in general conditions. Overfitting happens when a model performs exceptionally well on training data but fares poorly with unseen data.
This aspect of AI models can be explained by the “Black Box Problem” – the idea that the internal workings of these AI systems is not clear. AI models have become so complex that even their developers can be unclear on how their model reaches a particular output. Transparency revolves around providing clarity on how the model makes its decisions and the kind of data it was trained on.
Ensuring transparency of AI models involves the following:
These documents should detail the purpose, limitations, performance metrics, and other aspects of the model.
There are certain techniques such as decision trees and model visualization tools that can help stakeholders understand the decision-making process used.
When the development process adheres to established regulations such as the EU’s AI Act, it ensures ethics in various aspects of the model’s behavior.
This aspect of responsible AI is concerned with safeguarding the user data that models work with. Standard frameworks such as GDPR outline on how personal information of users must be processed and stored.
Here’s how AI systems can ensure privacy of the users:
Only collect the data which is needed for the model’s purpose.
Hide and anonymize user data to prevent unauthorized access.
Conduct regular evaluations of these systems to identify and address potential privacy issues.
When privacy concerns are a core part of the whole development process, then measures are taken to ensure it at every step.
As most companies are looking to adopt AI in some shape or form, it is more crucial than ever to standardize ethics to develop responsible AI systems. In 2024, the integration of AI into business strategies has become common, with nearly half of technology leaders reporting full integration into their core operations.
However, this rapid integration has also highlighted major concerns. Issues such as algorithmic bias, lack of transparency, and potential misuse have prompted calls for ensuring ethical standards. Notably, experts like Yoshua Bengio have called for better oversight to tackle these risks.
Looking ahead, the below trends will forge the path for AI development going ahead:
Enhanced Autonomy: AI-powered agents are expected to perform tasks with higher independence, which will help in making workflows simpler.
Ethical Frameworks: There is growing importance being put on fair, accountable, and accessible AI frameworks, so that they balance quick innovation with ethical aspect.
Regulatory Developments: Governments and enterprises are expected to implement more robust regulations to ensure AI systems are developed and deployed responsibly.
Moving forward, enterprises will have to commit to responsible AI, to reach the full potential of artificial intelligence. By focusing on ethical principles and bringing the stakeholders on board, we can navigate this challenging time in the AI space, ensuring that it benefits all facets of society.


